Ganeti 2.1 design¶
This document describes the major changes in Ganeti 2.1 compared to the 2.0 version.
The 2.1 version will be a relatively small release. Its main aim is to avoid changing too much of the core code, while addressing issues and adding new features and improvements over 2.0, in a timely fashion.
Contents
Objective¶
Ganeti 2.1 will add features to help further automatization of cluster operations, further improve scalability to even bigger clusters, and make it easier to debug the Ganeti core.
Detailed design¶
As for 2.0 we divide the 2.1 design into three areas:
- core changes, which affect the master daemon/job queue/locking or all/most logical units
- logical unit/feature changes
- external interface changes (eg. command line, os api, hooks, ...)
Core changes¶
Storage units modelling¶
Currently, Ganeti has a good model of the block devices for instances (e.g. LVM logical volumes, files, DRBD devices, etc.) but none of the storage pools that are providing the space for these front-end devices. For example, there are hardcoded inter-node RPC calls for volume group listing, file storage creation/deletion, etc.
The storage units framework will implement a generic handling for all kinds of storage backends:
- LVM physical volumes
- LVM volume groups
- File-based storage directories
- any other future storage method
There will be a generic list of methods that each storage unit type will provide, like:
- list of storage units of this type
- check status of the storage unit
Additionally, there will be specific methods for each method, for example:
- enable/disable allocations on a specific PV
- file storage directory creation/deletion
- VG consistency fixing
This will allow a much better modeling and unification of the various RPC calls related to backend storage pool in the future. Ganeti 2.1 is intended to add the basics of the framework, and not necessarilly move all the curent VG/FileBased operations to it.
Note that while we model both LVM PVs and LVM VGs, the framework will not model any relationship between the different types. In other words, we don’t model neither inheritances nor stacking, since this is too complex for our needs. While a vgreduce operation on a LVM VG could actually remove a PV from it, this will not be handled at the framework level, but at individual operation level. The goal is that this is a lightweight framework, for abstracting the different storage operation, and not for modelling the storage hierarchy.
Locking improvements¶
Current State and shortcomings¶
The class LockSet (see lib/locking.py) is a container for one or many SharedLock instances. It provides an interface to add/remove locks and to acquire and subsequently release any number of those locks contained in it.
Locks in a LockSet are always acquired in alphabetic order. Due to the way we’re using locks for nodes and instances (the single cluster lock isn’t affected by this issue) this can lead to long delays when acquiring locks if another operation tries to acquire multiple locks but has to wait for yet another operation.
In the following demonstration we assume to have the instance locks inst1, inst2, inst3 and inst4.
- Operation A grabs lock for instance inst4.
- Operation B wants to acquire all instance locks in alphabetic order, but it has to wait for inst4.
- Operation C tries to lock inst1, but it has to wait until Operation B (which is trying to acquire all locks) releases the lock again.
- Operation A finishes and releases lock on inst4. Operation B can continue and eventually releases all locks.
- Operation C can get inst1 lock and finishes.
Technically there’s no need for Operation C to wait for Operation A, and subsequently Operation B, to finish. Operation B can’t continue until Operation A is done (it has to wait for inst4), anyway.
Proposed changes¶
Non-blocking lock acquiring¶
Acquiring locks for OpCode execution is always done in blocking mode. They won’t return until the lock has successfully been acquired (or an error occurred, although we won’t cover that case here).
SharedLock and LockSet must be able to be acquired in a non-blocking way. They must support a timeout and abort trying to acquire the lock(s) after the specified amount of time.
Retry acquiring locks¶
To prevent other operations from waiting for a long time, such as described in the demonstration before, LockSet must not keep locks for a prolonged period of time when trying to acquire two or more locks. Instead it should, with an increasing timeout for acquiring all locks, release all locks again and sleep some time if it fails to acquire all requested locks.
A good timeout value needs to be determined. In any case should LockSet proceed to acquire locks in blocking mode after a few (unsuccessful) attempts to acquire all requested locks.
One proposal for the timeout is to use 2**tries seconds, where tries is the number of unsuccessful tries.
In the demonstration before this would allow Operation C to continue after Operation B unsuccessfully tried to acquire all locks and released all acquired locks (inst1, inst2 and inst3) again.
Other solutions discussed¶
There was also some discussion on going one step further and extend the job queue (see lib/jqueue.py) to select the next task for a worker depending on whether it can acquire the necessary locks. While this may reduce the number of necessary worker threads and/or increase throughput on large clusters with many jobs, it also brings many potential problems, such as contention and increased memory usage, with it. As this would be an extension of the changes proposed before it could be implemented at a later point in time, but we decided to stay with the simpler solution for now.
Implementation details¶
SharedLock redesign¶
The current design of SharedLock is not good for supporting timeouts when acquiring a lock and there are also minor fairness issues in it. We plan to address both with a redesign. A proof of concept implementation was written and resulted in significantly simpler code.
Currently SharedLock uses two separate queues for shared and exclusive acquires and waiters get to run in turns. This means if an exclusive acquire is released, the lock will allow shared waiters to run and vice versa. Although it’s still fair in the end there is a slight bias towards shared waiters in the current implementation. The same implementation with two shared queues can not support timeouts without adding a lot of complexity.
Our proposed redesign changes SharedLock to have only one single queue. There will be one condition (see Condition for a note about performance) in the queue per exclusive acquire and two for all shared acquires (see below for an explanation). The maximum queue length will always be 2 + (number of exclusive acquires waiting). The number of queue entries for shared acquires can vary from 0 to 2.
The two conditions for shared acquires are a bit special. They will be used in turn. When the lock is instantiated, no conditions are in the queue. As soon as the first shared acquire arrives (and there are holder(s) or waiting acquires; see Acquire), the active condition is added to the queue. Until it becomes the topmost condition in the queue and has been notified, any shared acquire is added to this active condition. When the active condition is notified, the conditions are swapped and further shared acquires are added to the previously inactive condition (which has now become the active condition). After all waiters on the previously active (now inactive) and now notified condition received the notification, it is removed from the queue of pending acquires.
This means shared acquires will skip any exclusive acquire in the queue. We believe it’s better to improve parallelization on operations only asking for shared (or read-only) locks. Exclusive operations holding the same lock can not be parallelized.
For exclusive acquires a new condition is created and appended to the queue. Shared acquires are added to the active condition for shared acquires and if the condition is not yet on the queue, it’s appended.
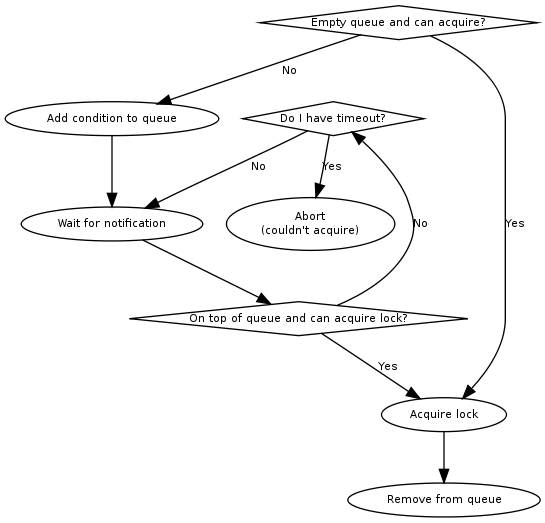
The next step is to wait for our condition to be on the top of the queue (to guarantee fairness). If the timeout expired, we return to the caller without acquiring the lock. On every notification we check whether the lock has been deleted, in which case an error is returned to the caller.
The lock can be acquired if we’re on top of the queue (there is no one else ahead of us). For an exclusive acquire, there must not be other exclusive or shared holders. For a shared acquire, there must not be an exclusive holder. If these conditions are all true, the lock is acquired and we return to the caller. In any other case we wait again on the condition.
If it was the last waiter on a condition, the condition is removed from the queue.
Optimization: There’s no need to touch the queue if there are no pending acquires and no current holders. The caller can have the lock immediately.
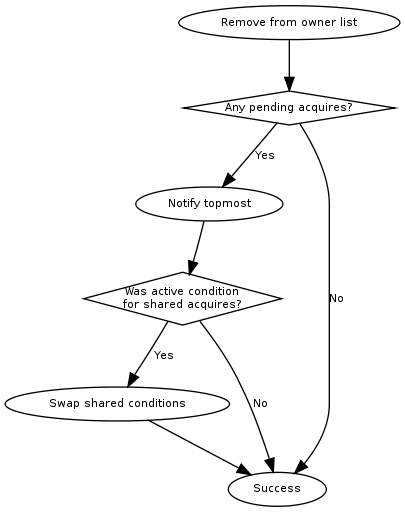
First the lock removes the caller from the internal owner list. If there are pending acquires in the queue, the first (the oldest) condition is notified.
If the first condition was the active condition for shared acquires, the inactive condition will be made active. This ensures fairness with exclusive locks by forcing consecutive shared acquires to wait in the queue.
The caller must either hold the lock in exclusive mode already or the lock must be acquired in exclusive mode. Trying to delete a lock while it’s held in shared mode must fail.
After ensuring the lock is held in exclusive mode, the lock will mark itself as deleted and continue to notify all pending acquires. They will wake up, notice the deleted lock and return an error to the caller.
Condition¶
Note: This is not necessary for the locking changes above, but it may be a good optimization (pending performance tests).
The existing locking code in Ganeti 2.0 uses Python’s built-in threading.Condition class. Unfortunately Condition implements timeouts by sleeping 1ms to 20ms between tries to acquire the condition lock in non-blocking mode. This requires unnecessary context switches and contention on the CPython GIL (Global Interpreter Lock).
By using POSIX pipes (see pipe(2)) we can use the operating system’s support for timeouts on file descriptors (see select(2)). A custom condition class will have to be written for this.
On instantiation the class creates a pipe. After each notification the previous pipe is abandoned and re-created (technically the old pipe needs to stay around until all notifications have been delivered).
All waiting clients of the condition use select(2) or poll(2) to wait for notifications, optionally with a timeout. A notification will be signalled to the waiting clients by closing the pipe. If the pipe wasn’t closed during the timeout, the waiting function returns to its caller nonetheless.
Node daemon availability¶
Current State and shortcomings¶
Currently, when a Ganeti node suffers serious system disk damage, the migration/failover of an instance may not correctly shutdown the virtual machine on the broken node causing instances duplication. The gnt-node powercycle command can be used to force a node reboot and thus to avoid duplicated instances. This command relies on node daemon availability, though, and thus can fail if the node daemon has some pages swapped out of ram, for example.
Proposed changes¶
The proposed solution forces node daemon to run exclusively in RAM. It uses python ctypes to to call mlockall(MCL_CURRENT | MCL_FUTURE) on the node daemon process and all its children. In addition another log handler has been implemented for node daemon to redirect to /dev/console messages that cannot be written on the logfile.
With these changes node daemon can successfully run basic tasks such as a powercycle request even when the system disk is heavily damaged and reading/writing to disk fails constantly.
New Features¶
Automated Ganeti Cluster Merger¶
Current situation¶
Currently there’s no easy way to merge two or more clusters together. But in order to optimize resources this is a needed missing piece. The goal of this design doc is to come up with a easy to use solution which allows you to merge two or more cluster together.
Initial contact¶
As the design of Ganeti is based on an autonomous system, Ganeti by itself has no way to reach nodes outside of its cluster. To overcome this situation we’re required to prepare the cluster before we can go ahead with the actual merge: We’ve to replace at least the ssh keys on the affected nodes before we can do any operation within gnt- commands.
To make this a automated process we’ll ask the user to provide us with the root password of every cluster we’ve to merge. We use the password to grab the current id_dsa key and then rely on that ssh key for any further communication to be made until the cluster is fully merged.
Cluster merge¶
After initial contact we do the cluster merge:
- Grab the list of nodes
- On all nodes add our own id_dsa.pub key to authorized_keys
- Stop all instances running on the merging cluster
- Disable ganeti-watcher as it tries to restart Ganeti daemons
- Stop all Ganeti daemons on all merging nodes
- Grab the config.data from the master of the merging cluster
- Stop local ganeti-masterd
- Merge the config:
- Open our own cluster config.data
- Open cluster config.data of the merging cluster
- Grab all nodes of the merging cluster
- Set master_candidate to false on all merging nodes
- Add the nodes to our own cluster config.data
- Grab all the instances on the merging cluster
- Adjust the port if the instance has drbd layout:
- In logical_id (index 2)
- In physical_id (index 1 and 3)
- Add the instances to our own cluster config.data
- Start ganeti-masterd with --no-voting --yes-do-it
- gnt-node add --readd on all merging nodes
- gnt-cluster redist-conf
- Restart ganeti-masterd normally
- Enable ganeti-watcher again
- Start all merging instances again
Rollback¶
Until we actually (re)add any nodes we can abort and rollback the merge at any point. After merging the config, though, we’ve to get the backup copy of config.data (from another master candidate node). And for security reasons it’s a good idea to undo id_dsa.pub distribution by going on every affected node and remove the id_dsa.pub key again. Also we’ve to keep in mind, that we’ve to start the Ganeti daemons and starting up the instances again.
Verification¶
Last but not least we should verify that the merge was successful. Therefore we run gnt-cluster verify, which ensures that the cluster overall is in a healthy state. Additional it’s also possible to compare the list of instances/nodes with a list made prior to the upgrade to make sure we didn’t lose any data/instance/node.
Appendix¶
cluster-merge.py¶
Used to merge the cluster config. This is a POC and might differ from actual production code.
#!/usr/bin/python
import sys
from ganeti import config
from ganeti import constants
c_mine = config.ConfigWriter(offline=True)
c_other = config.ConfigWriter(sys.argv[1])
fake_id = 0
for node in c_other.GetNodeList():
node_info = c_other.GetNodeInfo(node)
node_info.master_candidate = False
c_mine.AddNode(node_info, str(fake_id))
fake_id += 1
for instance in c_other.GetInstanceList():
instance_info = c_other.GetInstanceInfo(instance)
for dsk in instance_info.disks:
if dsk.dev_type in constants.LDS_DRBD:
port = c_mine.AllocatePort()
logical_id = list(dsk.logical_id)
logical_id[2] = port
dsk.logical_id = tuple(logical_id)
physical_id = list(dsk.physical_id)
physical_id[1] = physical_id[3] = port
dsk.physical_id = tuple(physical_id)
c_mine.AddInstance(instance_info, str(fake_id))
fake_id += 1
Feature changes¶
Ganeti Confd¶
Current State and shortcomings¶
In Ganeti 2.0 all nodes are equal, but some are more equal than others. In particular they are divided between “master”, “master candidates” and “normal”. (Moreover they can be offline or drained, but this is not important for the current discussion). In general the whole configuration is only replicated to master candidates, and some partial information is spread to all nodes via ssconf.
This change was done so that the most frequent Ganeti operations didn’t need to contact all nodes, and so clusters could become bigger. If we want more information to be available on all nodes, we need to add more ssconf values, which is counter-balancing the change, or to talk with the master node, which is not designed to happen now, and requires its availability.
Information such as the instance->primary_node mapping will be needed on all nodes, and we also want to make sure services external to the cluster can query this information as well. This information must be available at all times, so we can’t query it through RAPI, which would be a single point of failure, as it’s only available on the master.
Proposed changes¶
In order to allow fast and highly available access read-only to some configuration values, we’ll create a new ganeti-confd daemon, which will run on master candidates. This daemon will talk via UDP, and authenticate messages using HMAC with a cluster-wide shared key. This key will be generated at cluster init time, and stored on the clusters alongside the ganeti SSL keys, and readable only by root.
An interested client can query a value by making a request to a subset of the cluster master candidates. It will then wait to get a few responses, and use the one with the highest configuration serial number. Since the configuration serial number is increased each time the ganeti config is updated, and the serial number is included in all answers, this can be used to make sure to use the most recent answer, in case some master candidates are stale or in the middle of a configuration update.
In order to prevent replay attacks queries will contain the current unix timestamp according to the client, and the server will verify that its timestamp is in the same 5 minutes range (this requires synchronized clocks, which is a good idea anyway). Queries will also contain a “salt” which they expect the answers to be sent with, and clients are supposed to accept only answers which contain salt generated by them.
The configuration daemon will be able to answer simple queries such as:
- master candidates list
- master node
- offline nodes
- instance list
- instance primary nodes
Wire protocol¶
A confd query will look like this, on the wire:
plj0{
"msg": "{\"type\": 1,
\"rsalt\": \"9aa6ce92-8336-11de-af38-001d093e835f\",
\"protocol\": 1,
\"query\": \"node1.example.com\"}\n",
"salt": "1249637704",
"hmac": "4a4139b2c3c5921f7e439469a0a45ad200aead0f"
}
“plj0” is a fourcc that details the message content. It stands for plain json 0, and can be changed as we move on to different type of protocols (for example protocol buffers, or encrypted json). What follows is a json encoded string, with the following fields:
- ‘msg’ contains a JSON-encoded query, its fields are:
- ‘protocol’, integer, is the confd protocol version (initially just constants.CONFD_PROTOCOL_VERSION, with a value of 1)
- ‘type’, integer, is the query type. For example “node role by name” or “node primary ip by instance ip”. Constants will be provided for the actual available query types.
- ‘query’, string, is the search key. For example an ip, or a node name.
- ‘rsalt’, string, is the required response salt. The client must use it to recognize which answer it’s getting.
- ‘salt’ must be the current unix timestamp, according to the client. Servers can refuse messages which have a wrong timing, according to their configuration and clock.
- ‘hmac’ is an hmac signature of salt+msg, with the cluster hmac key
If an answer comes back (which is optional, since confd works over UDP) it will be in this format:
plj0{
"msg": "{\"status\": 0,
\"answer\": 0,
\"serial\": 42,
\"protocol\": 1}\n",
"salt": "9aa6ce92-8336-11de-af38-001d093e835f",
"hmac": "aaeccc0dff9328fdf7967cb600b6a80a6a9332af"
}
Where:
- ‘plj0’ the message type magic fourcc, as discussed above
- ‘msg’ contains a JSON-encoded answer, its fields are:
- ‘protocol’, integer, is the confd protocol version (initially just constants.CONFD_PROTOCOL_VERSION, with a value of 1)
- ‘status’, integer, is the error code. Initially just 0 for ‘ok’ or ‘1’ for ‘error’ (in which case answer contains an error detail, rather than an answer), but in the future it may be expanded to have more meanings (eg: 2, the answer is compressed)
- ‘answer’, is the actual answer. Its type and meaning is query specific. For example for “node primary ip by instance ip” queries it will be a string containing an IP address, for “node role by name” queries it will be an integer which encodes the role (master, candidate, drained, offline) according to constants.
- ‘salt’ is the requested salt from the query. A client can use it to recognize what query the answer is answering.
- ‘hmac’ is an hmac signature of salt+msg, with the cluster hmac key
Redistribute Config¶
Current State and shortcomings¶
Currently LUClusterRedistConf triggers a copy of the updated configuration file to all master candidates and of the ssconf files to all nodes. There are other files which are maintained manually but which are important to keep in sync. These are:
- rapi SSL key certificate file (rapi.pem) (on master candidates)
- rapi user/password file rapi_users (on master candidates)
Furthermore there are some files which are hypervisor specific but we may want to keep in sync:
- the xen-hvm hypervisor uses one shared file for all vnc passwords, and copies the file once, during node add. This design is subject to revision to be able to have different passwords for different groups of instances via the use of hypervisor parameters, and to allow xen-hvm and kvm to use an equal system to provide password-protected vnc sessions. In general, though, it would be useful if the vnc password files were copied as well, to avoid unwanted vnc password changes on instance failover/migrate.
Optionally the admin may want to also ship files such as the global xend.conf file, and the network scripts to all nodes.
Proposed changes¶
RedistributeConfig will be changed to copy also the rapi files, and to call every enabled hypervisor asking for a list of additional files to copy. Users will have the possibility to populate a file containing a list of files to be distributed; this file will be propagated as well. Such solution is really simple to implement and it’s easily usable by scripts.
This code will be also shared (via tasklets or by other means, if tasklets are not ready for 2.1) with the AddNode and SetNodeParams LUs (so that the relevant files will be automatically shipped to new master candidates as they are set).
VNC Console Password¶
Current State and shortcomings¶
Currently just the xen-hvm hypervisor supports setting a password to connect the the instances’ VNC console, and has one common password stored in a file.
This doesn’t allow different passwords for different instances/groups of instances, and makes it necessary to remember to copy the file around the cluster when the password changes.
Proposed changes¶
We’ll change the VNC password file to a vnc_password_file hypervisor parameter. This way it can have a cluster default, but also a different value for each instance. The VNC enabled hypervisors (xen and kvm) will publish all the password files in use through the cluster so that a redistribute-config will ship them to all nodes (see the Redistribute Config proposed changes above).
The current VNC_PASSWORD_FILE constant will be removed, but its value will be used as the default HV_VNC_PASSWORD_FILE value, thus retaining backwards compatibility with 2.0.
The code to export the list of VNC password files from the hypervisors to RedistributeConfig will be shared between the KVM and xen-hvm hypervisors.
Disk/Net parameters¶
Current State and shortcomings¶
Currently disks and network interfaces have a few tweakable options and all the rest is left to a default we chose. We’re finding that we need more and more to tweak some of these parameters, for example to disable barriers for DRBD devices, or allow striping for the LVM volumes.
Moreover for many of these parameters it will be nice to have cluster-wide defaults, and then be able to change them per disk/interface.
Proposed changes¶
We will add new cluster level diskparams and netparams, which will contain all the tweakable parameters. All values which have a sensible cluster-wide default will go into this new structure while parameters which have unique values will not.
- Example of network parameters:
- mode: bridge/route
- link: for mode “bridge” the bridge to connect to, for mode route it can contain the routing table, or the destination interface
- Example of disk parameters:
- stripe: lvm stripes
- stripe_size: lvm stripe size
- meta_flushes: drbd, enable/disable metadata “barriers”
- data_flushes: drbd, enable/disable data “barriers”
Some parameters are bound to be disk-type specific (drbd, vs lvm, vs files) or hypervisor specific (nic models for example), but for now they will all live in the same structure. Each component is supposed to validate only the parameters it knows about, and ganeti itself will make sure that no “globally unknown” parameters are added, and that no parameters have overridden meanings for different components.
The parameters will be kept, as for the BEPARAMS into a “default” category, which will allow us to expand on by creating instance “classes” in the future. Instance classes is not a feature we plan implementing in 2.1, though.
Global hypervisor parameters¶
Current State and shortcomings¶
Currently all hypervisor parameters are modifiable both globally (cluster level) and at instance level. However, there is no other framework to held hypervisor-specific parameters, so if we want to add a new class of hypervisor parameters that only makes sense on a global level, we have to change the hvparams framework.
Proposed changes¶
We add a new (global, not per-hypervisor) list of parameters which are not changeable on a per-instance level. The create, modify and query instance operations are changed to not allow/show these parameters.
Furthermore, to allow transition of parameters to the global list, and to allow cleanup of inadverdently-customised parameters, the UpgradeConfig() method of instances will drop any such parameters from their list of hvparams, such that a restart of the master daemon is all that is needed for cleaning these up.
Also, the framework is simple enough that if we need to replicate it at beparams level we can do so easily.
Non bridged instances support¶
Current State and shortcomings¶
Currently each instance NIC must be connected to a bridge, and if the bridge is not specified the default cluster one is used. This makes it impossible to use the vif-route xen network scripts, or other alternative mechanisms that don’t need a bridge to work.
Proposed changes¶
The new “mode” network parameter will distinguish between bridged interfaces and routed ones.
When mode is “bridge” the “link” parameter will contain the bridge the instance should be connected to, effectively making things as today. The value has been migrated from a nic field to a parameter to allow for an easier manipulation of the cluster default.
When mode is “route” the ip field of the interface will become mandatory, to allow for a route to be set. In the future we may want also to accept multiple IPs or IP/mask values for this purpose. We will evaluate possible meanings of the link parameter to signify a routing table to be used, which would allow for insulation between instance groups (as today happens for different bridges).
For now we won’t add a parameter to specify which network script gets called for which instance, so in a mixed cluster the network script must be able to handle both cases. The default kvm vif script will be changed to do so. (Xen doesn’t have a ganeti provided script, so nothing will be done for that hypervisor)
Introducing persistent UUIDs¶
Current state and shortcomings¶
Some objects in the Ganeti configurations are tracked by their name while also supporting renames. This creates an extra difficulty, because neither Ganeti nor external management tools can then track the actual entity, and due to the name change it behaves like a new one.
Proposed changes part 1¶
We will change Ganeti to use UUIDs for entity tracking, but in a staggered way. In 2.1, we will simply add an “uuid” attribute to each of the instances, nodes and cluster itself. This will be reported on instance creation for nodes, and on node adds for the nodes. It will be of course avaiblable for querying via the OpNodeQuery/Instance and cluster information, and via RAPI as well.
Note that Ganeti will not provide any way to change this attribute.
Upgrading from Ganeti 2.0 will automatically add an ‘uuid’ attribute to all entities missing it.
Proposed changes part 2¶
In the next release (e.g. 2.2), the tracking of objects will change from the name to the UUID internally, and externally Ganeti will accept both forms of identification; e.g. an RAPI call would be made either against /2/instances/foo.bar or against /2/instances/bb3b2e42…. Since an FQDN must have at least a dot, and dots are not valid characters in UUIDs, we will not have namespace issues.
Another change here is that node identification (during cluster operations/queries like master startup, “am I the master?” and similar) could be done via UUIDs which is more stable than the current hostname-based scheme.
Internal tracking refers to the way the configuration is stored; a DRBD disk of an instance refers to the node name (so that IPs can be changed easily), but this is still a problem for name changes; thus these will be changed to point to the node UUID to ease renames.
The advantages of this change (after the second round of changes), is that node rename becomes trivial, whereas today node rename would require a complete lock of all instances.
Automated disk repairs infrastructure¶
Replacing defective disks in an automated fashion is quite difficult with the current version of Ganeti. These changes will introduce additional functionality and interfaces to simplify automating disk replacements on a Ganeti node.
Fix node volume group¶
This is the most difficult addition, as it can lead to dataloss if it’s not properly safeguarded.
The operation must be done only when all the other nodes that have instances in common with the target node are fine, i.e. this is the only node with problems, and also we have to double-check that all instances on this node have at least a good copy of the data.
This might mean that we have to enhance the GetMirrorStatus calls, and introduce and a smarter version that can tell us more about the status of an instance.
Stop allocation on a given PV¶
This is somewhat simple. First we need a “list PVs” opcode (and its associated logical unit) and then a set PV status opcode/LU. These in combination should allow both checking and changing the disk/PV status.
Instance disk status¶
This new opcode or opcode change must list the instance-disk-index and node combinations of the instance together with their status. This will allow determining what part of the instance is broken (if any).
Repair instance¶
This new opcode/LU/RAPI call will run replace-disks -p as needed, in order to fix the instance status. It only affects primary instances; secondaries can just be moved away.
Migrate node¶
This new opcode/LU/RAPI call will take over the current gnt-node migrate code and run migrate for all instances on the node.
Evacuate node¶
This new opcode/LU/RAPI call will take over the current gnt-node evacuate code and run replace-secondary with an iallocator script for all instances on the node.
User-id pool¶
In order to allow running different processes under unique user-ids on a node, we introduce the user-id pool concept.
The user-id pool is a cluster-wide configuration parameter. It is a list of user-ids and/or user-id ranges that are reserved for running Ganeti processes (including KVM instances). The code guarantees that on a given node a given user-id is only handed out if there is no other process running with that user-id.
Please note, that this can only be guaranteed if all processes in the system - that run under a user-id belonging to the pool - are started by reserving a user-id first. That can be accomplished either by using the RequestUnusedUid() function to get an unused user-id or by implementing the same locking mechanism.
Implementation¶
The functions that are specific to the user-id pool feature are located in a separate module: lib/uidpool.py.
Storage¶
The user-id pool is a single cluster parameter. It is stored in the Cluster object under the uid_pool name as a list of integer tuples. These tuples represent the boundaries of user-id ranges. For single user-ids, the boundaries are equal.
The internal user-id pool representation is converted into a string: a newline separated list of user-ids or user-id ranges. This string representation is distributed to all the nodes via the ssconf mechanism. This means that the user-id pool can be accessed in a read-only way on any node without consulting the master node or master candidate nodes.
Initial value¶
The value of the user-id pool cluster parameter can be initialized at cluster initialization time using the
gnt-cluster init --uid-pool <uid-pool definition> ...
command.
As there is no sensible default value for the user-id pool parameter, it is initialized to an empty list if no --uid-pool option is supplied at cluster init time.
If the user-id pool is empty, the user-id pool feature is considered to be disabled.
Manipulation¶
The user-id pool cluster parameter can be modified from the command-line with the following commands:
- gnt-cluster modify --uid-pool <uid-pool definition>
- gnt-cluster modify --add-uids <uid-pool definition>
- gnt-cluster modify --remove-uids <uid-pool definition>
The --uid-pool option overwrites the current setting with the supplied <uid-pool definition>, while --add-uids/--remove-uids adds/removes the listed uids or uid-ranges from the pool.
The <uid-pool definition> should be a comma-separated list of user-ids or user-id ranges. A range should be defined by a lower and a higher boundary. The boundaries should be separated with a dash. The boundaries are inclusive.
The <uid-pool definition> is parsed into the internal representation, sanity-checked and stored in the uid_pool attribute of the Cluster object.
It is also immediately converted into a string (formatted in the input format) and distributed to all nodes via the ssconf mechanism.
Inspection¶
The current value of the user-id pool cluster parameter is printed by the gnt-cluster info command.
The output format is accepted by the gnt-cluster modify --uid-pool command.
Locking¶
The uidpool.py module provides a function (RequestUnusedUid) for requesting an unused user-id from the pool.
This will try to find a random user-id that is not currently in use. The algorithm is the following:
- Randomize the list of user-ids in the user-id pool
- Iterate over this randomized UID list
- Create a lock file (it doesn’t matter if it already exists)
- Acquire an exclusive POSIX lock on the file, to provide mutual exclusion for the following non-atomic operations
- Check if there is a process in the system with the given UID
- If there isn’t, return the UID, otherwise unlock the file and continue the iteration over the user-ids
The user can than start a new process with this user-id. Once a process is successfully started, the exclusive POSIX lock can be released, but the lock file will remain in the filesystem. The presence of such a lock file means that the given user-id is most probably in use. The lack of a uid lock file does not guarantee that there are no processes with that user-id.
After acquiring the exclusive POSIX lock, RequestUnusedUid always performs a check to see if there is a process running with the given uid.
A user-id can be returned to the pool, by calling the ReleaseUid function. This will remove the corresponding lock file. Note, that it doesn’t check if there is any process still running with that user-id. The removal of the lock file only means that there are most probably no processes with the given user-id. This helps in speeding up the process of finding a user-id that is guaranteed to be unused.
There is a convenience function, called ExecWithUnusedUid that wraps the execution of a function (or any callable) that requires a unique user-id. ExecWithUnusedUid takes care of requesting an unused user-id and unlocking the lock file. It also automatically returns the user-id to the pool if the callable raises an exception.
Code examples¶
Requesting a user-id from the pool:
from ganeti import ssconf
from ganeti import uidpool
# Get list of all user-ids in the uid-pool from ssconf
ss = ssconf.SimpleStore()
uid_pool = uidpool.ParseUidPool(ss.GetUidPool(), separator="\n")
all_uids = set(uidpool.ExpandUidPool(uid_pool))
uid = uidpool.RequestUnusedUid(all_uids)
try:
<start a process with the UID>
# Once the process is started, we can release the file lock
uid.Unlock()
except ..., err:
# Return the UID to the pool
uidpool.ReleaseUid(uid)
Releasing a user-id:
from ganeti import uidpool
uid = <get the UID the process is running under>
<stop the process>
uidpool.ReleaseUid(uid)
External interface changes¶
OS API¶
The OS API of Ganeti 2.0 has been built with extensibility in mind. Since we pass everything as environment variables it’s a lot easier to send new information to the OSes without breaking retrocompatibility. This section of the design outlines the proposed extensions to the API and their implementation.
API Version Compatibility Handling¶
In 2.1 there will be a new OS API version (eg. 15), which should be mostly compatible with api 10, except for some new added variables. Since it’s easy not to pass some variables we’ll be able to handle Ganeti 2.0 OSes by just filtering out the newly added piece of information. We will still encourage OSes to declare support for the new API after checking that the new variables don’t provide any conflict for them, and we will drop api 10 support after ganeti 2.1 has released.
New Environment variables¶
Some variables have never been added to the OS api but would definitely be useful for the OSes. We plan to add an INSTANCE_HYPERVISOR variable to allow the OS to make changes relevant to the virtualization the instance is going to use. Since this field is immutable for each instance, the os can tight the install without caring of making sure the instance can run under any virtualization technology.
We also want the OS to know the particular hypervisor parameters, to be able to customize the install even more. Since the parameters can change, though, we will pass them only as an “FYI”: if an OS ties some instance functionality to the value of a particular hypervisor parameter manual changes or a reinstall may be needed to adapt the instance to the new environment. This is not a regression as of today, because even if the OSes are left blind about this information, sometimes they still need to make compromises and cannot satisfy all possible parameter values.
OS Variants¶
Currently we are assisting to some degree of “os proliferation” just to change a simple installation behavior. This means that the same OS gets installed on the cluster multiple times, with different names, to customize just one installation behavior. Usually such OSes try to share as much as possible through symlinks, but this still causes complications on the user side, especially when multiple parameters must be cross-matched.
For example today if you want to install debian etch, lenny or squeeze you probably need to install the debootstrap OS multiple times, changing its configuration file, and calling it debootstrap-etch, debootstrap-lenny or debootstrap-squeeze. Furthermore if you have for example a “server” and a “development” environment which installs different packages/configuration files and must be available for all installs you’ll probably end up with deboostrap-etch-server, debootstrap-etch-dev, debootrap-lenny-server, debootstrap-lenny-dev, etc. Crossing more than two parameters quickly becomes not manageable.
In order to avoid this we plan to make OSes more customizable, by allowing each OS to declare a list of variants which can be used to customize it. The variants list is mandatory and must be written, one variant per line, in the new “variants.list” file inside the main os dir. At least one supported variant must be supported. When choosing the OS exactly one variant will have to be specified, and will be encoded in the os name as <OS-name>+<variant>. As for today it will be possible to change an instance’s OS at creation or install time.
The 2.1 OS list will be the combination of each OS, plus its supported variants. This will cause the name name proliferation to remain, but at least the internal OS code will be simplified to just parsing the passed variant, without the need for symlinks or code duplication.
Also we expect the OSes to declare only “interesting” variants, but to accept some non-declared ones which a user will be able to pass in by overriding the checks ganeti does. This will be useful for allowing some variations to be used without polluting the OS list (per-OS documentation should list all supported variants). If a variant which is not internally supported is forced through, the OS scripts should abort.
In the future (post 2.1) we may want to move to full fledged parameters all orthogonal to each other (for example “architecture” (i386, amd64), “suite” (lenny, squeeze, ...), etc). (As opposed to the variant, which is a single parameter, and you need a different variant for all the set of combinations you want to support). In this case we envision the variants to be moved inside of Ganeti and be associated with lists parameter->values associations, which will then be passed to the OS.
IAllocator changes¶
Current State and shortcomings¶
The iallocator interface allows creation of instances without manually specifying nodes, but instead by specifying plugins which will do the required computations and produce a valid node list.
However, the interface is quite akward to use:
- one cannot set a ‘default’ iallocator script
- one cannot use it to easily test if allocation would succeed
- some new functionality, such as rebalancing clusters and calculating capacity estimates is needed
Proposed changes¶
There are two area of improvements proposed:
- improving the use of the current interface
- extending the IAllocator API to cover more automation
Default iallocator names¶
The cluster will hold, for each type of iallocator, a (possibly empty) list of modules that will be used automatically.
If the list is empty, the behaviour will remain the same.
If the list has one entry, then ganeti will behave as if ‘–iallocator’ was specifyed on the command line. I.e. use this allocator by default. If the user however passed nodes, those will be used in preference.
If the list has multiple entries, they will be tried in order until one gives a successful answer.
Dry-run allocation¶
The create instance LU will get a new ‘dry-run’ option that will just simulate the placement, and return the chosen node-lists after running all the usual checks.
Cluster balancing¶
Instance add/removals/moves can create a situation where load on the nodes is not spread equally. For this, a new iallocator mode will be implemented called balance in which the plugin, given the current cluster state, and a maximum number of operations, will need to compute the instance relocations needed in order to achieve a “better” (for whatever the script believes it’s better) cluster.
Cluster capacity calculation¶
In this mode, called capacity, given an instance specification and the current cluster state (similar to the allocate mode), the plugin needs to return:
- how many instances can be allocated on the cluster with that specification
- on which nodes these will be allocated (in order)